基于循环神经网络和全局注意力机制的雾霾预测模型
1. 数据获取及预处理
1.1 数据来源
该项目的数据主要来源是Pm25.in网站,数据获取方式为运用python的Beautiful Soup库对Pm25.in网站进行数据爬取。Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它是一个灵活又方便的网页解析库,处理高效,支持多种解析器。它能够通过转换器实现惯用的文档导航、查找及修改文档。
在使用多线程实现数据获取时,通过对共同访问的数据进行加锁,进行线程的同步,防止出现资源访问的错误。首先获取网页源码,采用python的urllib2模块对Pm25.in网站的网页源码进行获取。处理网页源码。运用Beautiful Soup库所提供的方法遍历源码,找到所需要的数据。利用python对文件的处理,将所需的原始数据写入记事本文件当中,供数据分析和雾霾预测使用。
1.2 数据说明
该网站数据丰富,共包括375座城市,1600个数据点。每个数据点包含监测点名称、时间、空气质量指数AQI、空气质量指数类别、首要污染物、PM2.5细颗粒物、PM10可吸入颗粒物、一氧化碳、二氧化氮、臭氧1小时平均、臭氧8小时平均、二氧化硫等十二项监测数据,符合对雾霾区域传输研究数据的要求,并且数据来源可靠、真实。Pm25.in网站是一个为广大应用开发者免费提供空气质量数据的一个公益性网站,Pm25.in的数据全部来源于网友提供的国家环保网站公开数据,网站会根据国家环保网站的实时数据进行二次核实。
数据获取的源码地址为 https://github.com/18811578511/DataMining_FogPredict/tree/master/data_get
1.3 数据预处理
在获取原始数据之后,进行数据预处理:
1)去除重复数据
首先需要去除数据文件中的重复行。获取数据的程序运行在阿里云的服务器上,虽然获取数据的程序在获取网页源码失败后可以自动重试,但是有时因为网络波动原因,还是会有一些时间段的数据缺失,为了防止数据缺失的情况发生,每隔一小时便再次运行该程序。这样数据缺失的问题得到了解决,但同时在得到的数据文件中会有重复的数据。所以首先对数据文件进行去重。按行读取文件,从首行开始,将原始文件的每一行存入列表中,如果新读取的行不存在于列表中,则将该行加入到列表中,将最终的列表写入到新的文件中,便得到了去除重复数据的监测点数据。
2)筛选所需数据
数据去重后,得到的是全国各个城市的监测点数据,需要从所有的监测点数据中得到北京市、天津市、河北省的各个监测点的数据,根据监测点名称对数据文件的每一行进行匹配,得到所需监测点的数据。在获取程序时,因为网络波动造成的程序中断,使得到的数据中有很多无效的数据,例如写入的数据只有一部分,在根据监测点名称进行匹配的同时,去除文件中的无效数据行,去除的判断依据有:使用制表符分割后是否为12列、分割后的第一组数据的长度是否为19(时间的格式)、分割后的第一组数据是否包含“2019”、分割后的每一组数据是否为空值(有空值则证明该行数据无效),也就是根据数据行的总列数、时间的完整性、每一个数据项的有效性对数据的有效性进行判断。经过监测点名称匹配和去除无效数据后,根据监测点名称列表对数据按照时间顺序进行保存。
3)均值补全数据
得到所需监测点的数据后,有的监测数据因为监测设备的问题会出现缺失的情况,在数据集中用“_”表示,因为训练数据是按照时间进行排序的,为了给预测模型提供完善的数据,对出现缺失的数值进行均值补全,即使用缺失数据的上一时刻和下一时刻的数值进行取平均,代替缺失的数据,当进行均值补全时,如果下一时刻的数据依然缺失,或者当前缺失的数据已经是最后一行数据,则使用上一时刻的数据代替当前缺失的数据。
4)归一化处理
不同的数据特征有着不同的评价指标,处于不同的数据范围,为了提高梯度下降求最优解的速度,使求解最优解的过程更容易收敛,对数据进行归一化处理。并且通过归一化也可以加强数据特征之间的综合对比和学习。归一化的数据范围为[0, 1]。对数据进行归一化之前,将监测点名称进行标签编码,将非数值类型的监测点名称转换为数值类型的数据,以便于进行归一化和数据的使用。最后将归一化处理后的数据,按照8:1:1的比例划分为训练集、验证集、测试集。
数据预处理的源码地址为https://github.com/18811578511/DataMining_FogPredict/tree/master/data_process
2. 数据分析与可视化
数据探索性分析的结果,可以使用统计工具,聚类分析等工具 使用可视化来展示分析结果
2.1 标称属性
1、总体情况
此数据集中,标称属性共2个,分别为地区和空气污染情况。
针对这2个标称属性,做一个整体的概览。
北京地区共17001条记录,河北地区共75044条记录,天津地区共10473条记录。
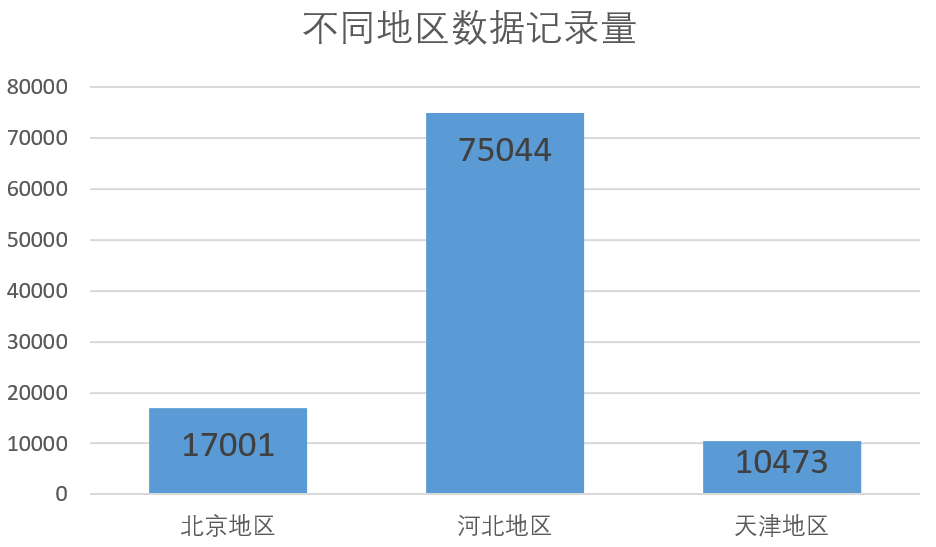
因记录数量差距较大,因此在对天气概况进行统计时,采用对北京、天津、河北三个地区的空气“优”占比情况做统计,结果如下。
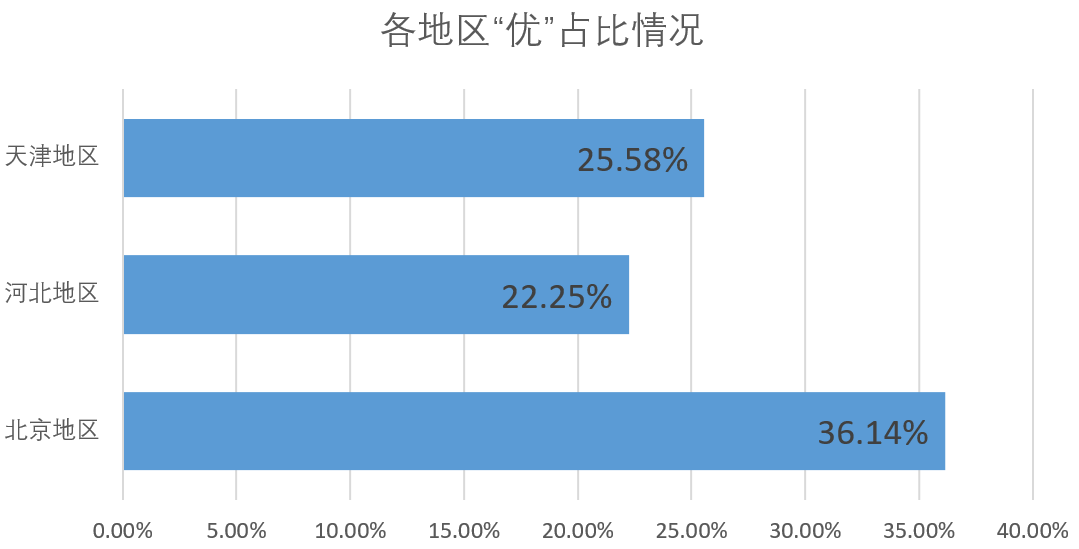
从结果中可得知,目前北京地区天气在这三个地区中还是较为优秀的,而河北地区天气“优”的天数占比较少,天气较差。
进一步分析,可将三个地区不同污染情况的占比情况进行对比。
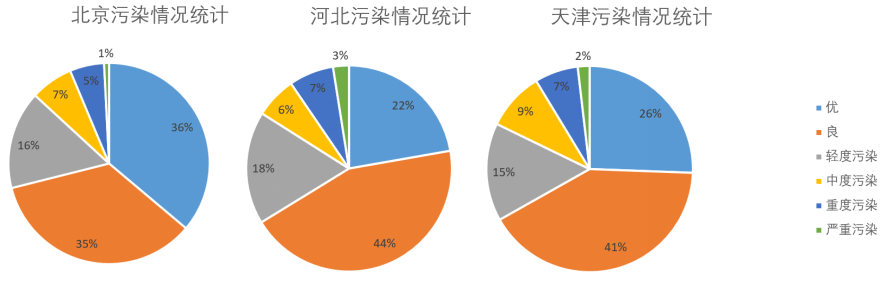
从结果中可得知,北京地区优良占比在三个地区中较大,而河北地区轻度污染占比在三个地区中较大,天津地区虽然轻度污染占比较小,但其中度污染占比在三个地区中最大,具体缘由可通过其他数据进行进一步分析。
2、北京地区情况
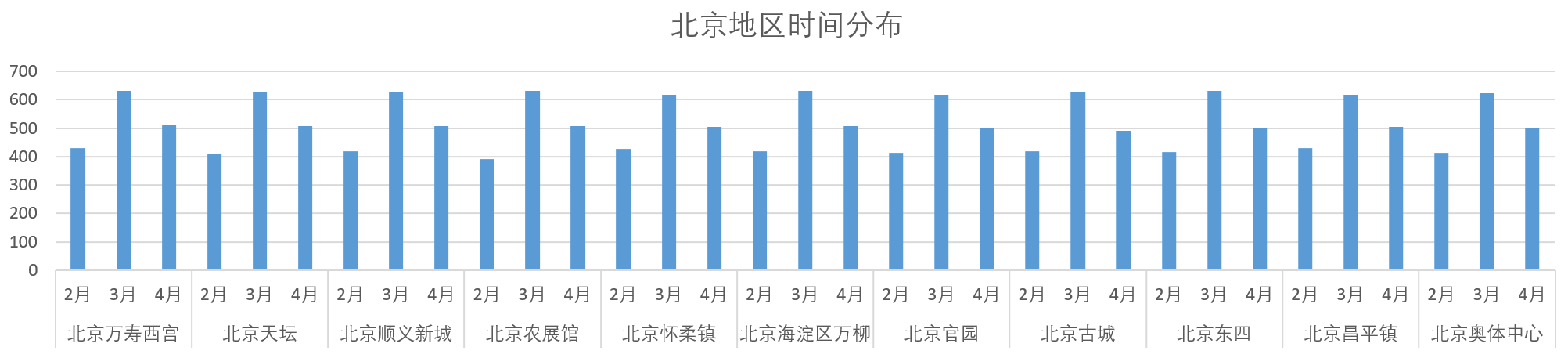
北京地区的数据共分为11个小区域进行统计,分布情况如下。
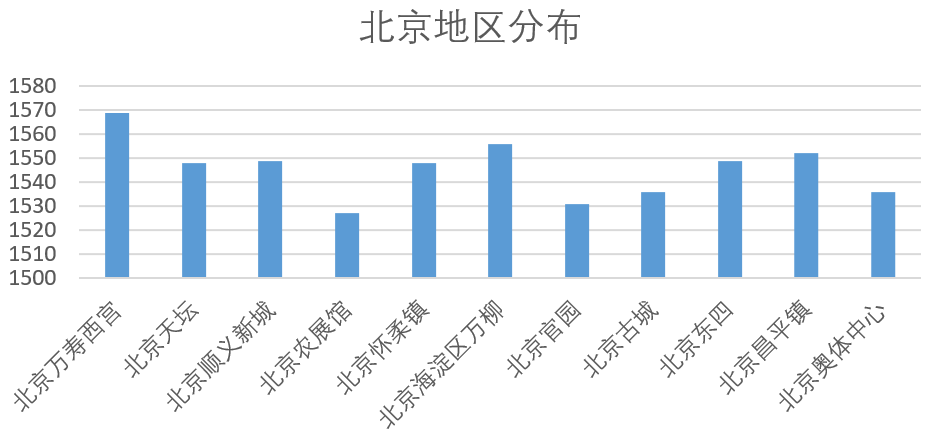
数据收集共分为2、3、4月,通过以下结果的显示,可判断每个地区的收集时间分布均匀,不存在偏差。
然后,对北京地区的污染情况进行统计,结果如下。
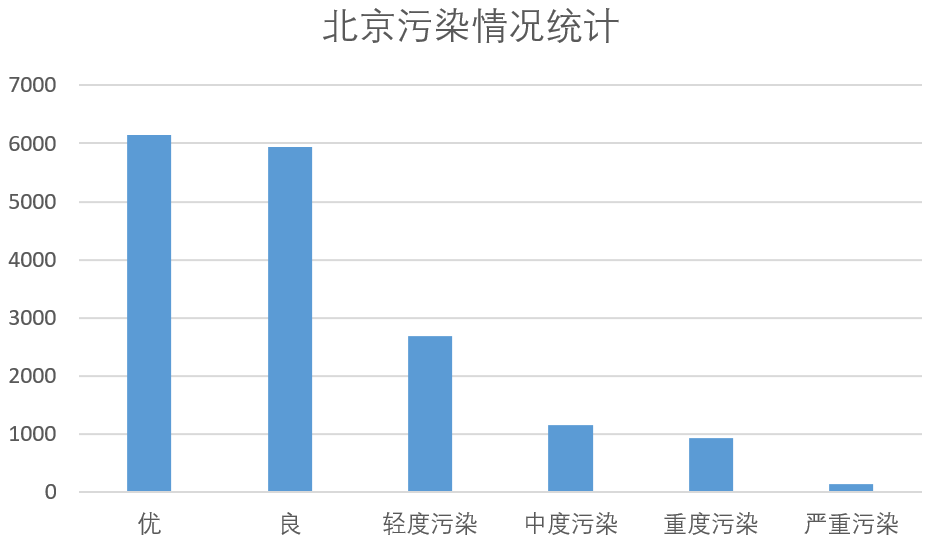
结果中可得知,北京地区天气“优”和天气“良”的数量最多,并明显领先于污染的天气数量。
在北京各地区中,北京怀柔镇的“优”数量最多,因其地理位置离城中心较远,污染情况较低。具体结果如下。
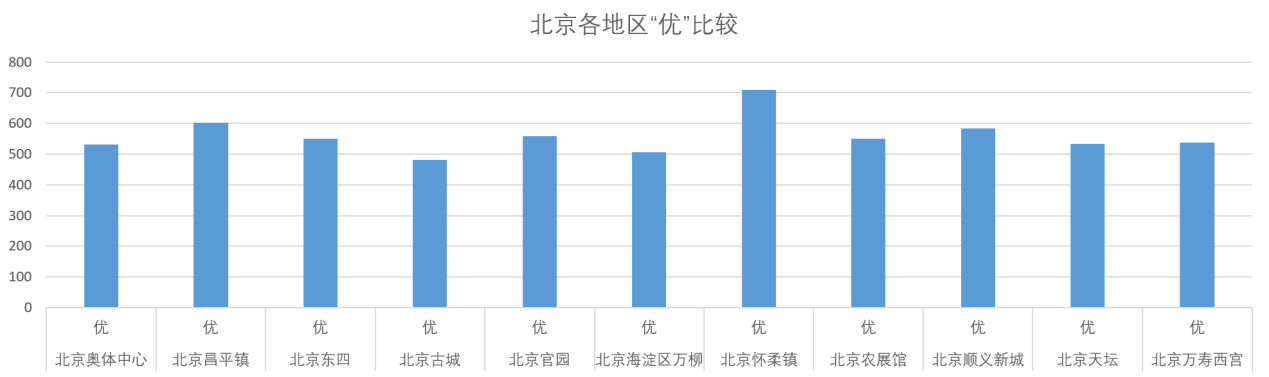
3、河北地区情况
河北地区的数据共分为11个小区域进行统计,分布情况如下。
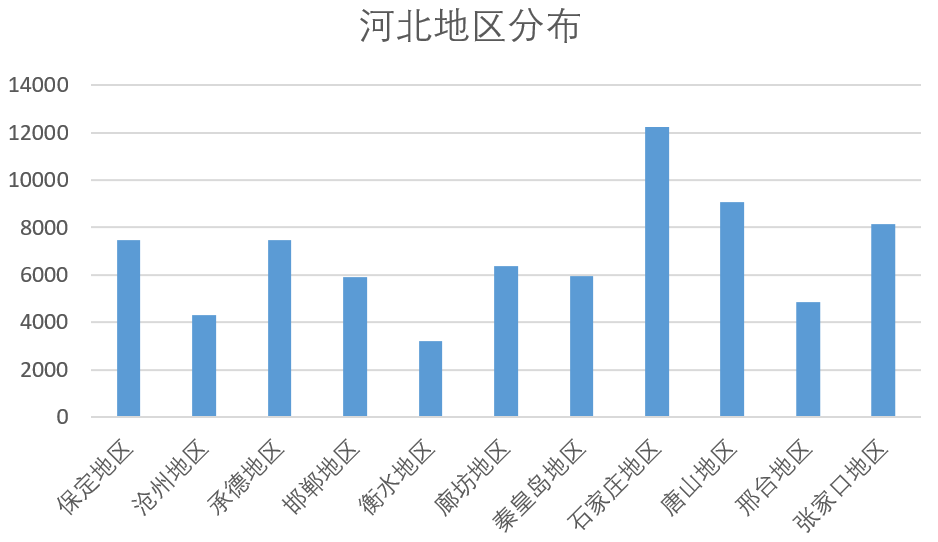
然后,对河北地区的污染情况进行统计,结果如下。
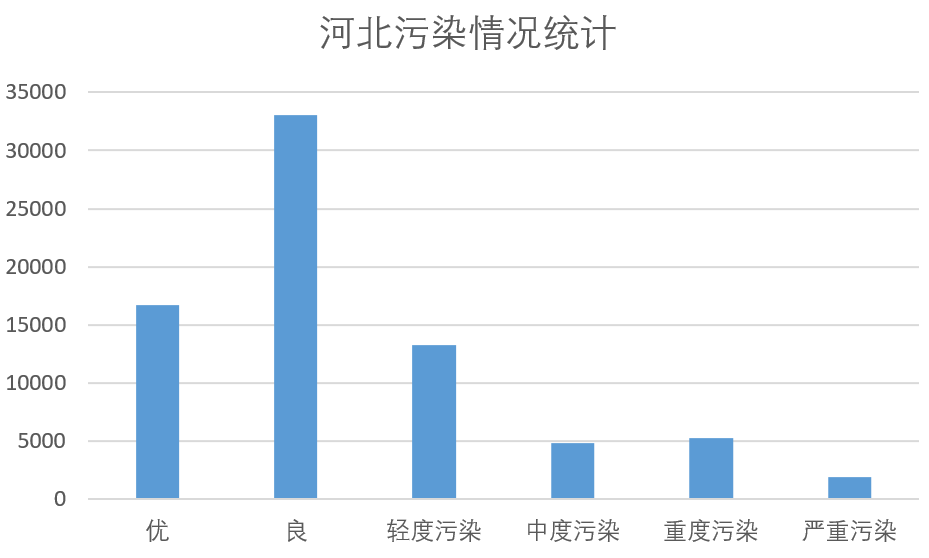
结果中可得知,河北地区天气“良”的数量最多,而天气“优”的数量则与“轻度污染”的数量较为接近,分析可认为河北地区污染情况较为严重。
4、天津地区情况
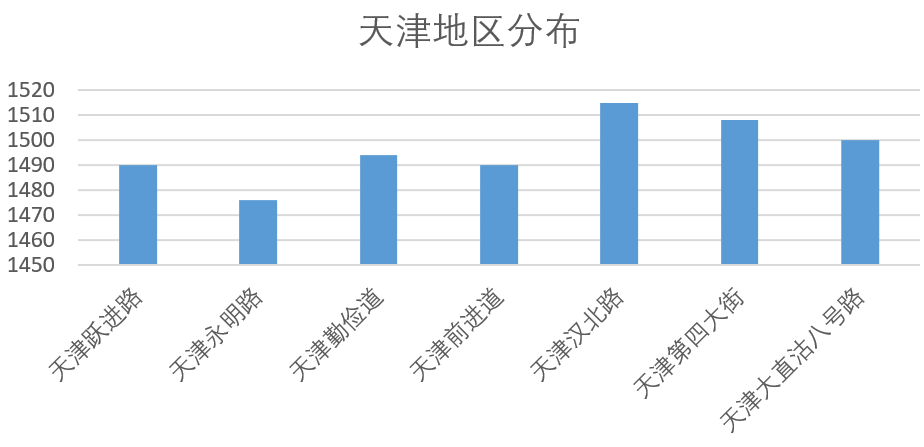
天津地区的数据共分为7个小区域进行统计,分布情况如下。
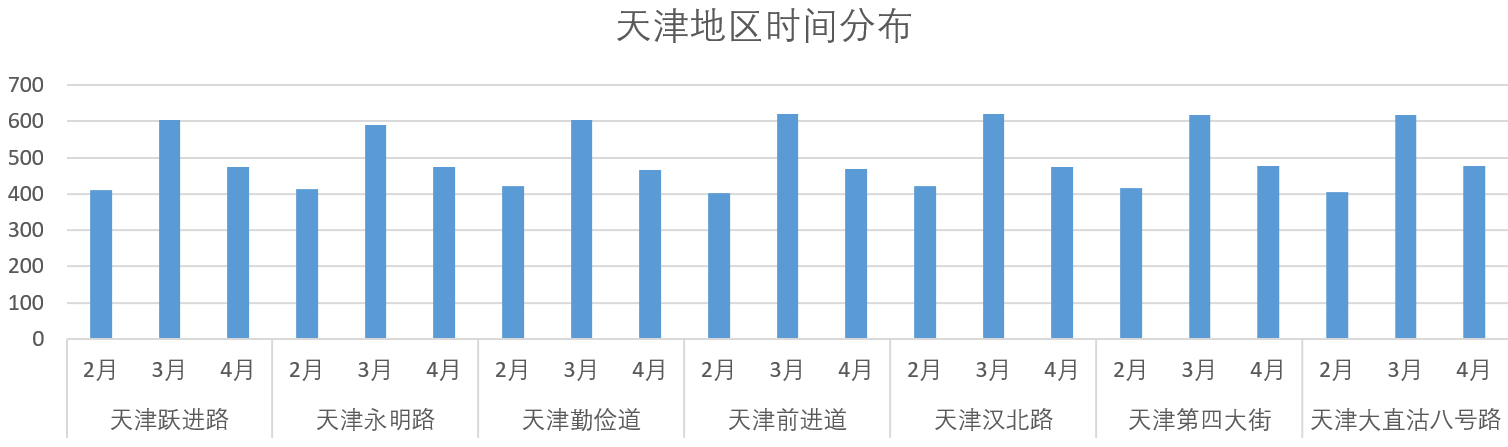
数据收集共分为2、3、4月,通过以下结果的显示,可判断每个地区的收集时间分布均匀,不存在偏差。
然后,对天津地区的污染情况进行统计,结果如下。
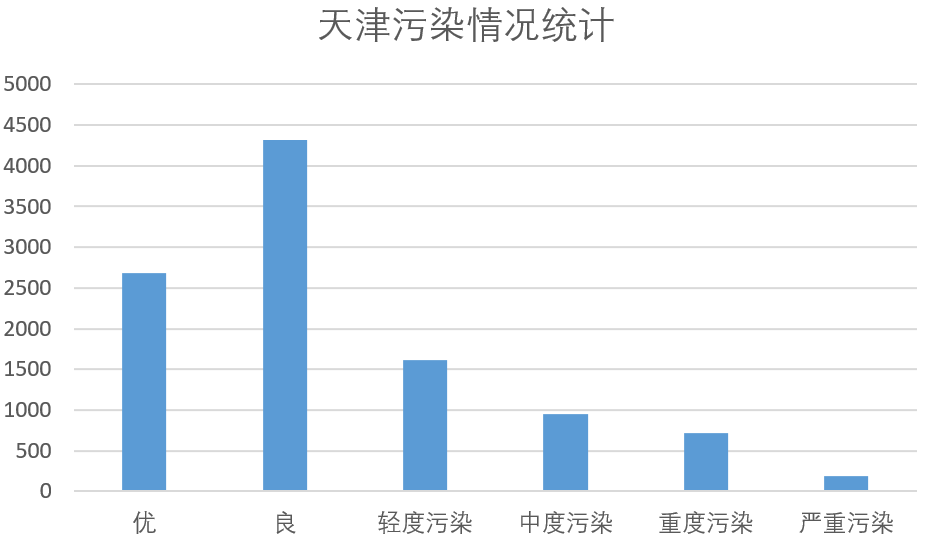
结果中可得知,天津地区天气“良”的数量最多,而天气“优”的数量与污染天气的数量相比较多,认为污染情况一般,但其“轻度污染”和“中度污染”的数量仍不可小觑,因此需要进一步的治理。
2.2 数值属性
下面我们针对数据中的数值数据进行分析。实验的数据中,数值属性共有8个,包括空气质量指数AQI以及空气检测各指标PM2.5、PM10、CO、NO2、O3_1、O3_8、SO2。
我们将对北京、河北、天津三大地区分别进行数据的分析以及可视化。
1、北京地区
首先对各检测指标进行分析。我们将各检测指标按照各项污染物的分级浓度限值以及数据自身特点进行分析。各项污染物的分级浓度限值如图所示。
整体数据分析
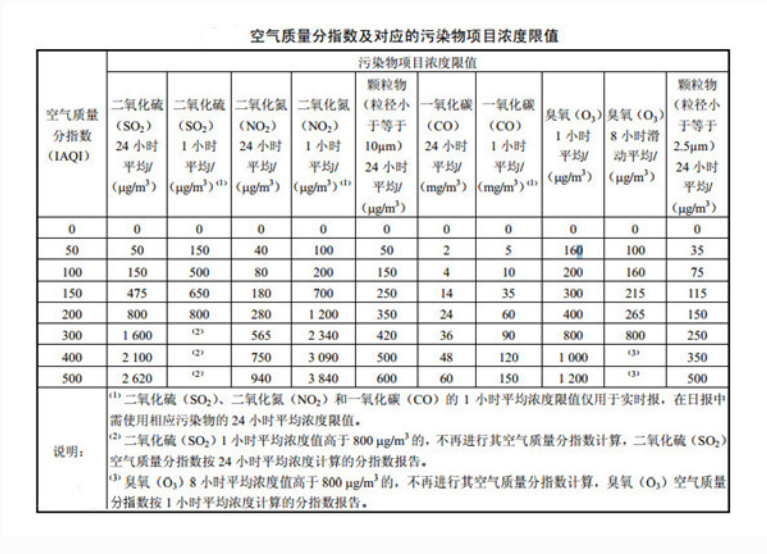
首先我们对整体数据进行分析,下图是北京地区AQI的盒图,从图中我们可以看到数据更加偏向于100以内,也就是空气质量在良以内。存在离群点属于中度及重度污染
下面我们针对各检测指标进行分析及可视化。
(1)PM 指标
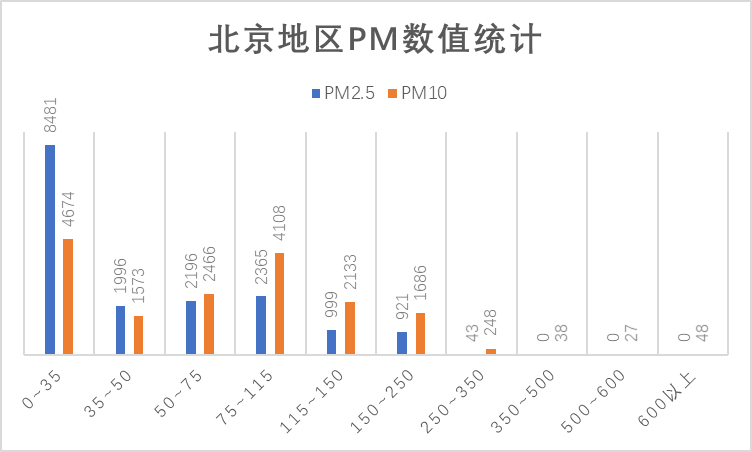
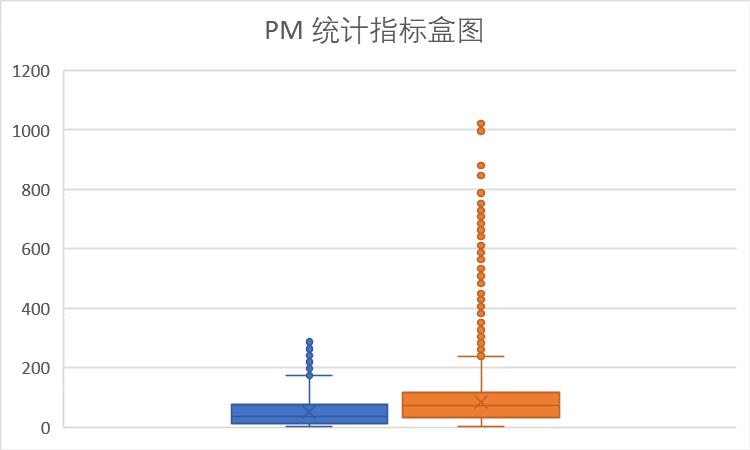
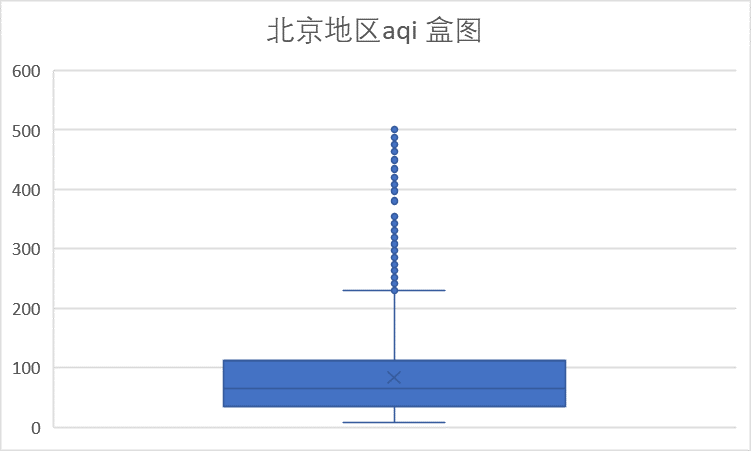
对照浓度限度表,从上面的数值统计图以及盒图我们可以看到,在PM指标上多数统计数据处于优良范围。
(2)CO 指标
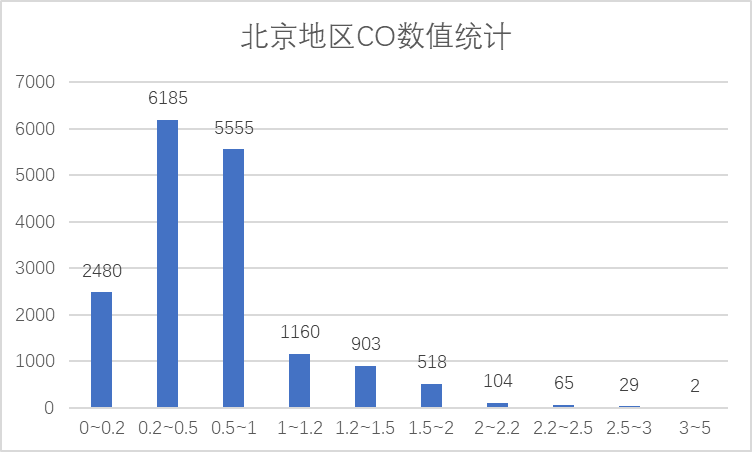
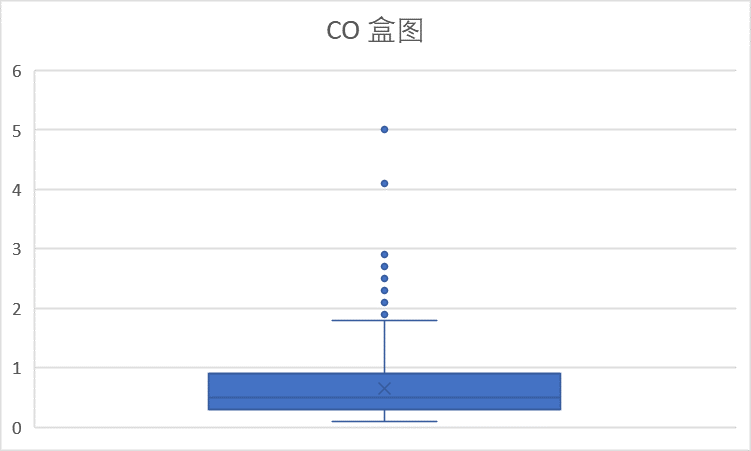
从上面两图可以看到CO指标大部分在优范围内的。
(3)NO2指标和O3 指标
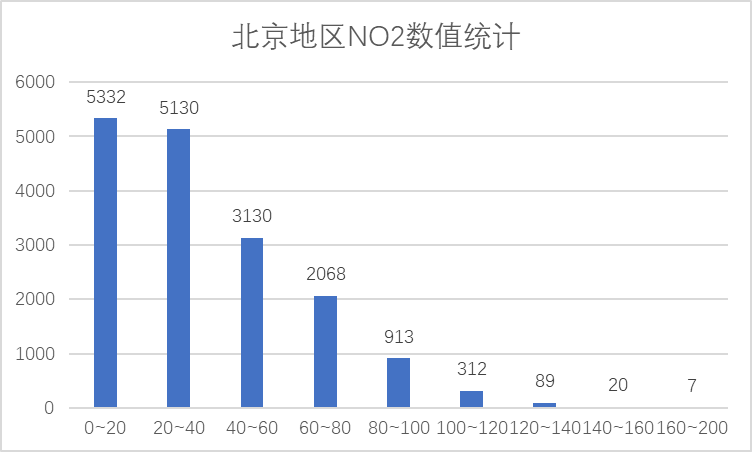
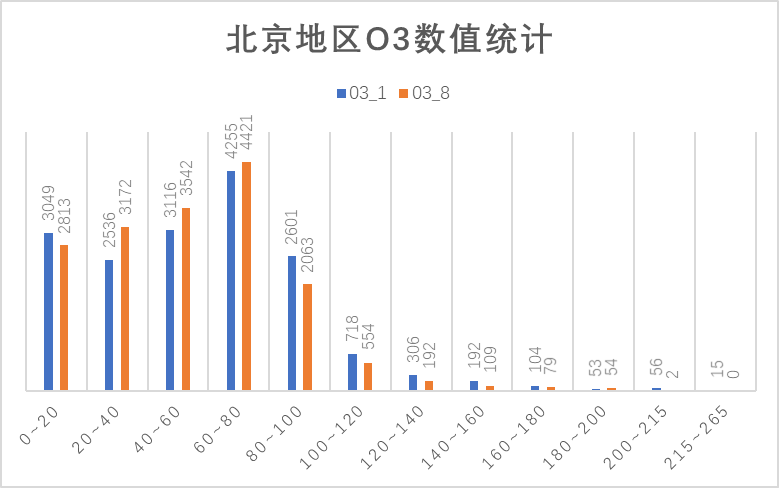
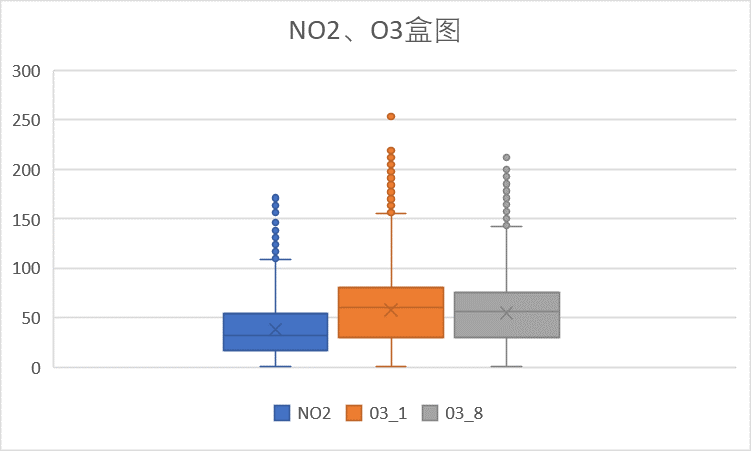
从上图可以看出,NO2大部分数据在100以内,100为优限度,因此NO2大部分在优秀范围内。O3指标包括O3_1和O3_8两部分,对照浓度限度,这两个指标同样在优范围内。
(4)SO2 指标
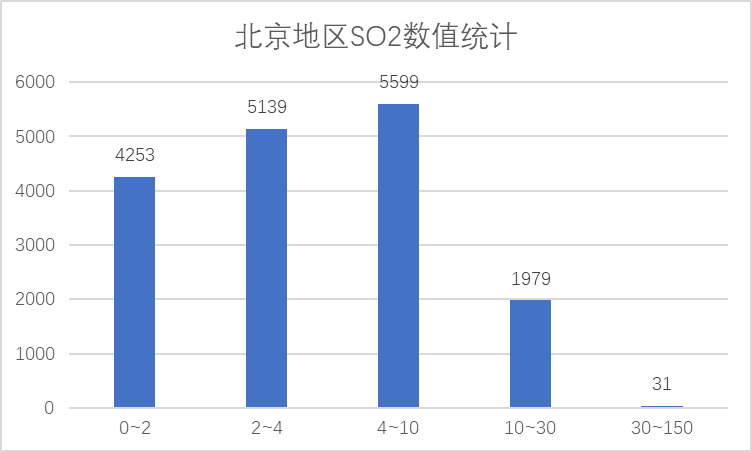
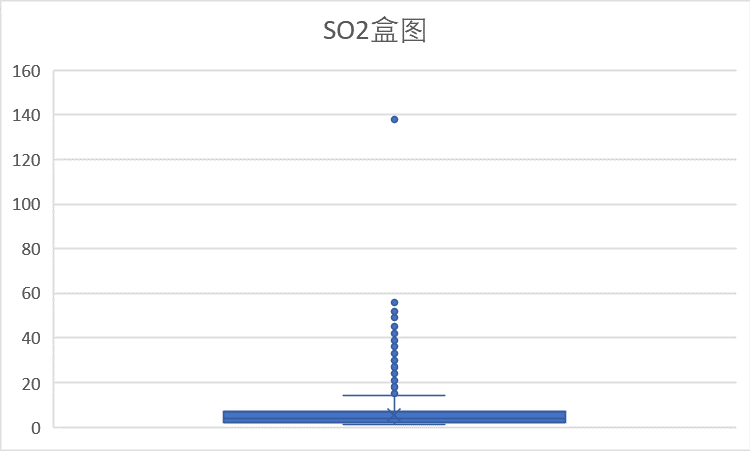
SO2浓度均在150以内,因此该指标同样在优范围之内,存在一个明显的离群点。
从以上分析中我们可以看到在统计时间内,北京地区的空气质量较好,多在良及以上。
各监测点分析
下面对各监测点AQI数据进行统计分析。
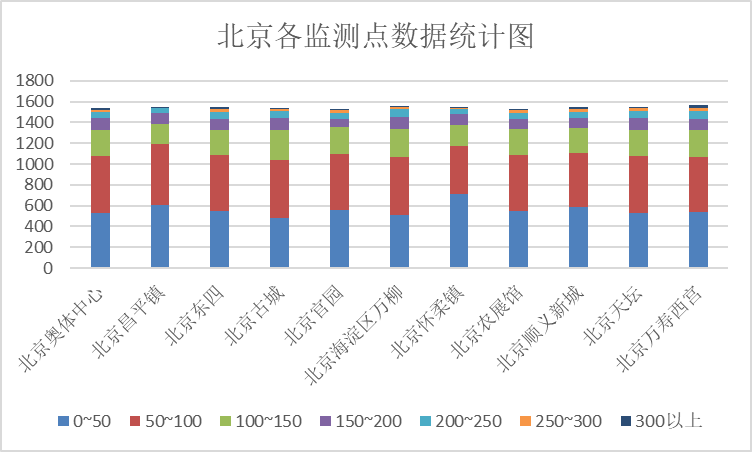
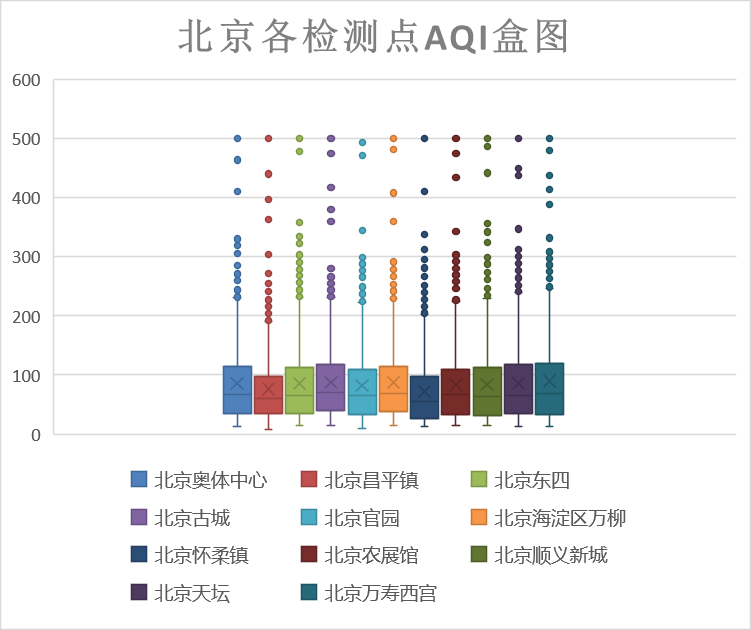
上图为各监测点的AQI数据统计,从图中我们可以看到,各监测点数据较为平均,空气质量为优及良的数量最多,存在轻度污染,中度污染和重度污染明显减少。
北京地区每月数据分析
(1)每月AQI分析
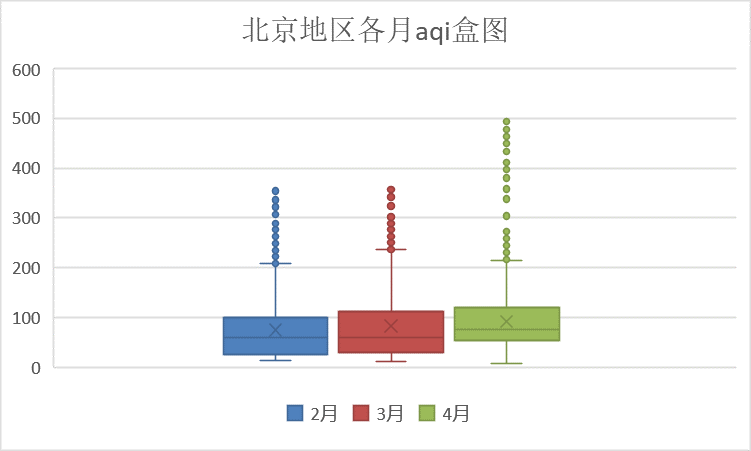
从盒图可以看出,2月和3月波动性不是很大,但4月存在明显的空气质量为严重污染的情况,离群点较多。
(2)各检测指标分析
下面我们针对各检测指标按时间进行分析。
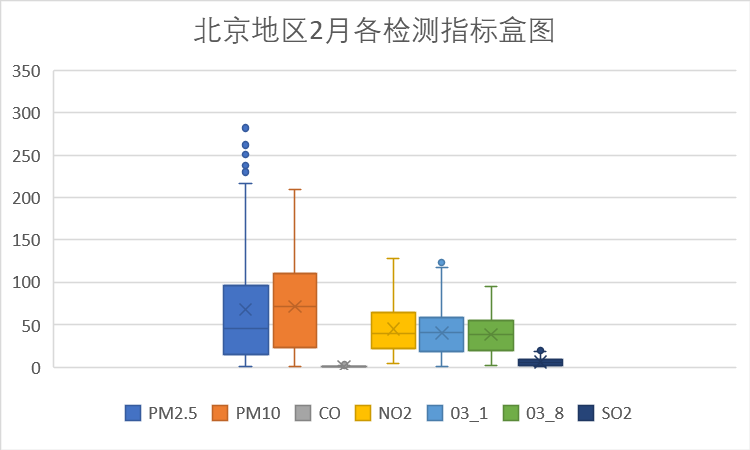
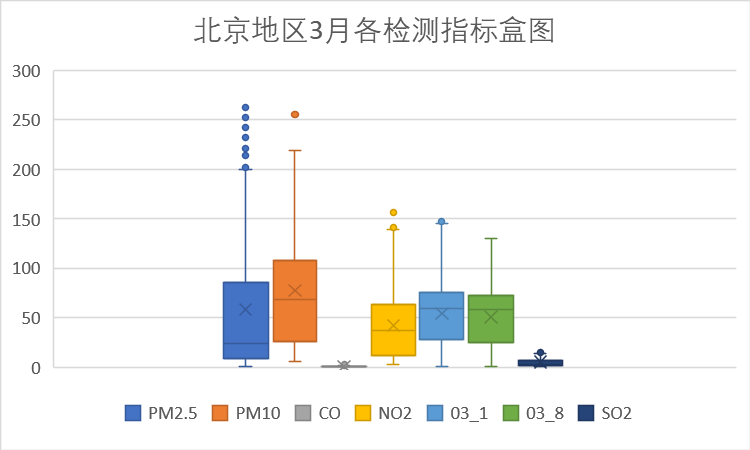
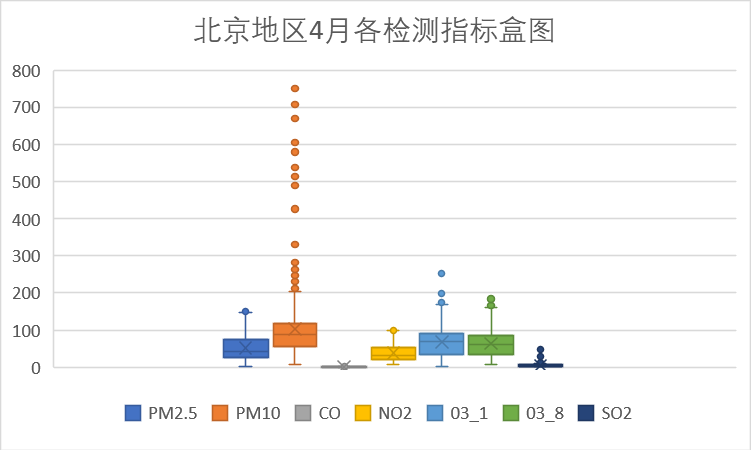
以上是每个月的各检测指标盒图,从图中可以看到PM10指标在4月存在偏高的数据,其余各检测指标无明显的波动。初步分析,4月AQI的波动缘于PM10的波动。
2、河北地区
下面我们对河北地区数据进行分析及可视化。
整体数据分析
首先我们对整体数据进行分析,下图是河北地区AQI的盒图,从图中我们可以看到数据更加偏向于150以内,也就是空气质量在轻度污染内,空气质量优的比例较小,存在中度及重度污染,同时严重污染也相对较多。可以看到河北地区整体的空气质量明显比北京地区差。
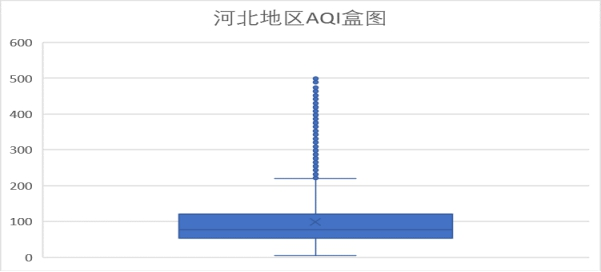
下面我们针对各检测指标进行分析及可视化。
(1)PM 指标
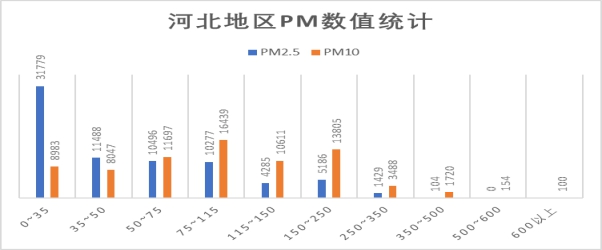
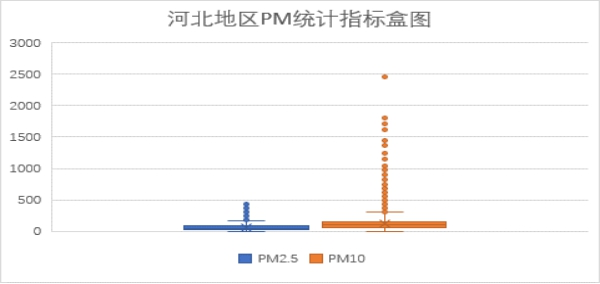
对照浓度限度表,从上面的数值统计图以及盒图我们可以看到,PM2.5指标数多在轻度污染内,且优良占比较高,PM10多在轻度污染内,且良占比较高。
(2)CO 指标
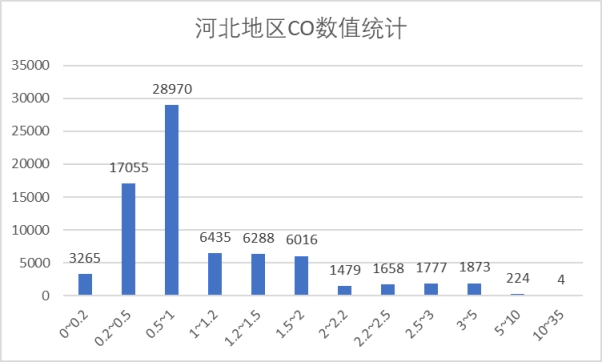
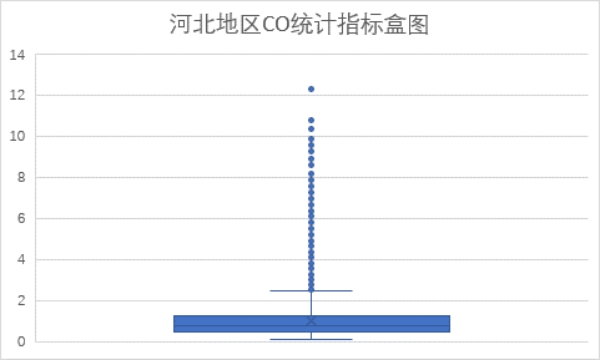
从上面两图可以看到CO指标全部在优于轻度污染,且多数数据小于良限度,优占比较高。
(3)NO2指标
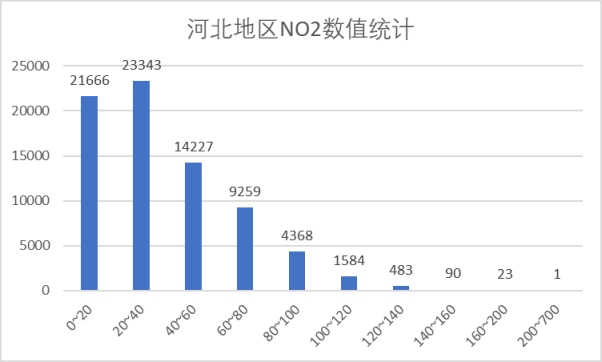
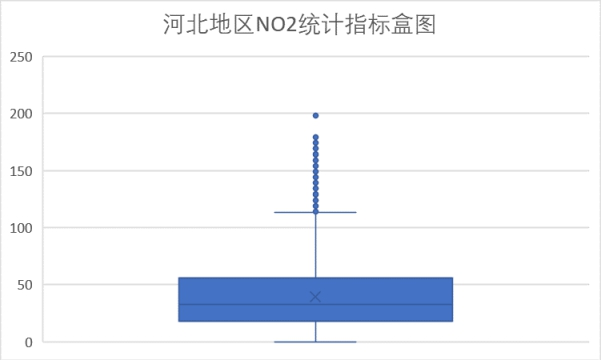
对照浓度限度表以及分析图我们可以看到,NO2统计指标小于200也就是良范围限值。
(4)O3指标
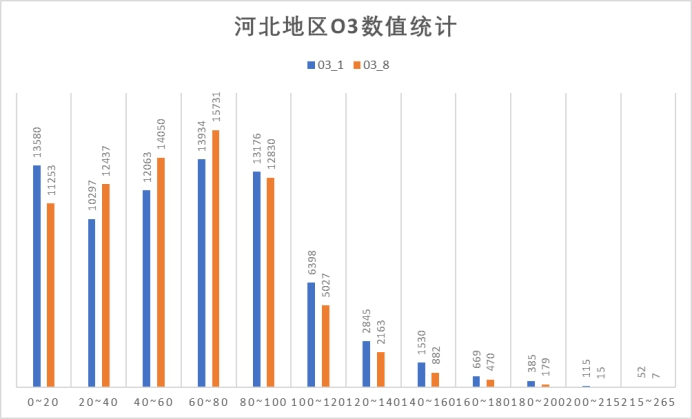
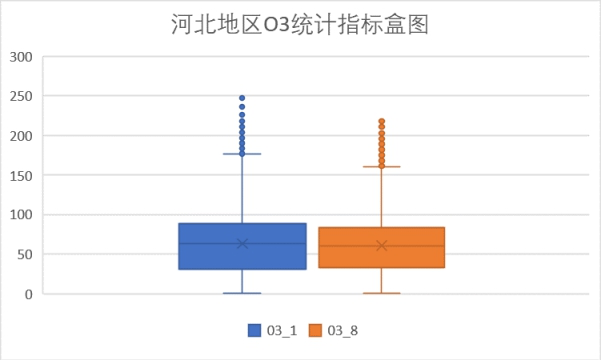
O3指标包括O3_1和O3_8两部分,对照浓度限度,O3_1多小于200,即在良范围内,存在部分数据在良限度和轻度污染限度之间。O3_8指标均小于215,即轻度污染范围内,且优良占比较高。
(5)SO2 指标
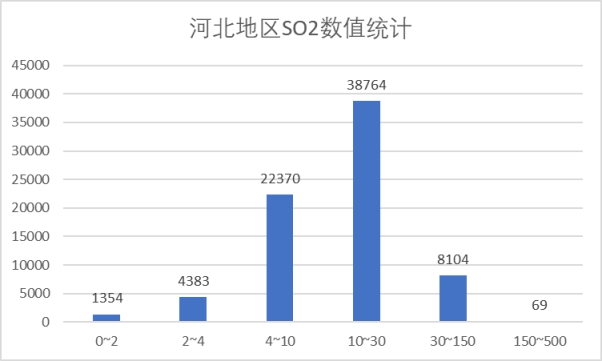
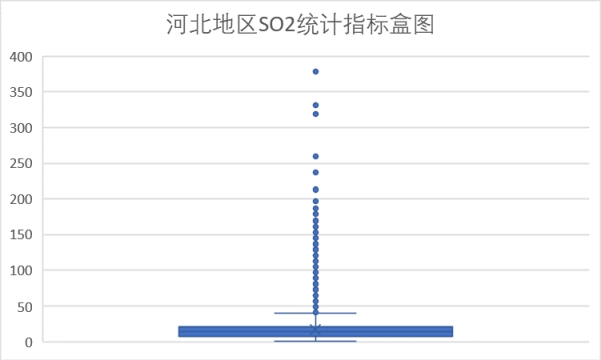
SO2浓度绝大部分在150以内,小部分在150-500范围内因此该指标同样在优良范围之内。
从以上分析中我们可以看到在统计时间内,河北地区的空气质量在各项指标上,多在轻度污染及以上,且良占比较高。从各指标看,河北地区的空气质量较北京差。
各监测点分析
下面对各监测点AQI数据进行统计分析。
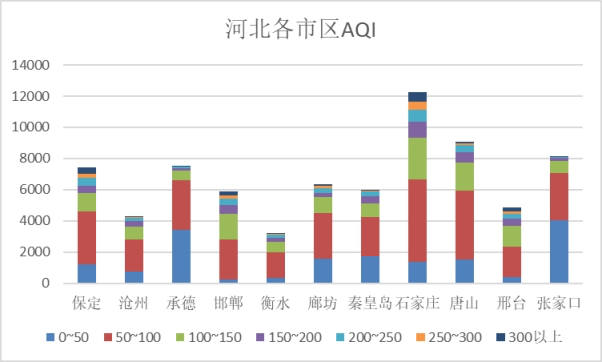
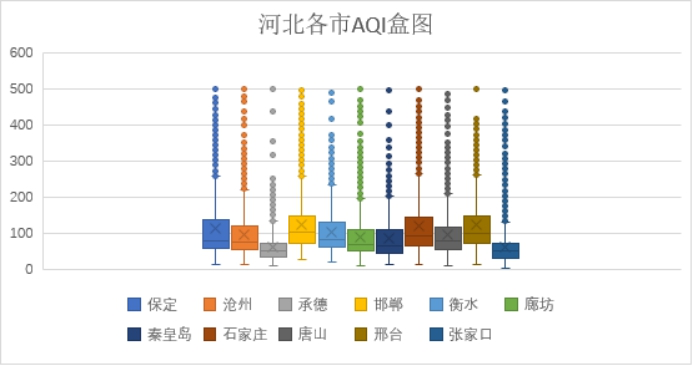
上图为各监测点的AQI数据统计,从图中我们可以看到,各监测点数据有所差别,大部分城市优占比较少,良占比较多,其中承德和张家口空气质量较其他城市好,相对空气质量较差的有石家庄和保定。
河北地区每月数据分析
(1)每月AQI分析
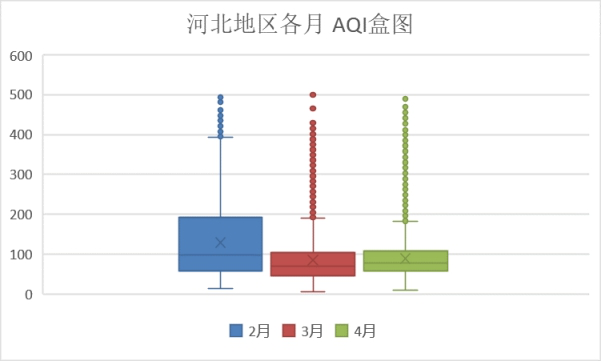
从盒图可以看出,3月和4月波动性不是很大,但2月的AQI整体偏向轻度污染。除此之外3、4月份的离群点较多。
(2)各检测指标分析
下面我们针对各检测指标按时间进行分析。
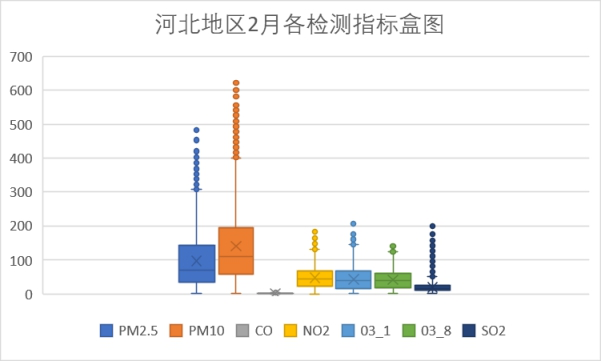
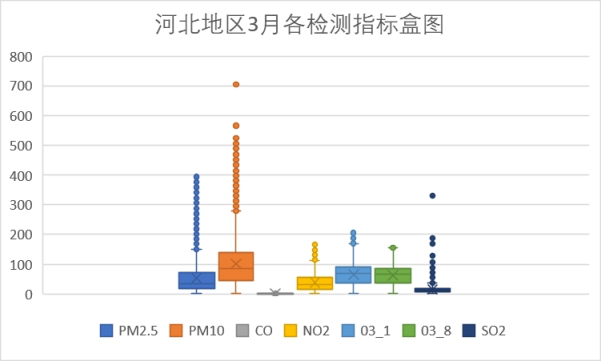
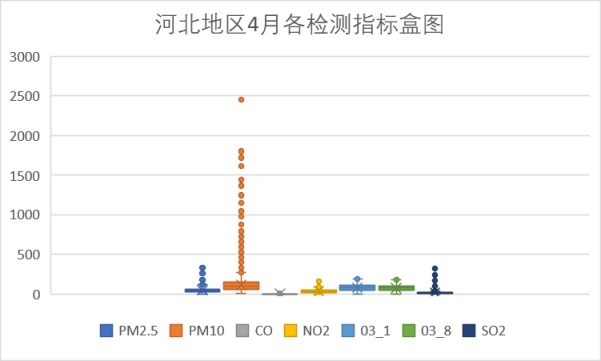
以上是每个月的各检测指标盒图,从图中可以看到PM10指标在4月存在偏高的数据,其余各检测指标无明显的波动。这和北京的情况相似。在河北空气主要的污染物为PM10,4月PM10的浓度较之前增高。
3、天津地区
下面我们对天津地区数据进行分析及可视化。
整体数据分析
首先我们对整体数据进行分析,下图是天津地区AQI的盒图,从图中我们可以看到数据更加偏向于150以内,也就是空气质量在轻度污染以内,空气质量良的比例较高,存在轻度、中度污染及重度污染,同时严重污染也相对较多。可以看到天津地区的空气质量也偏差,但较河北地区好。
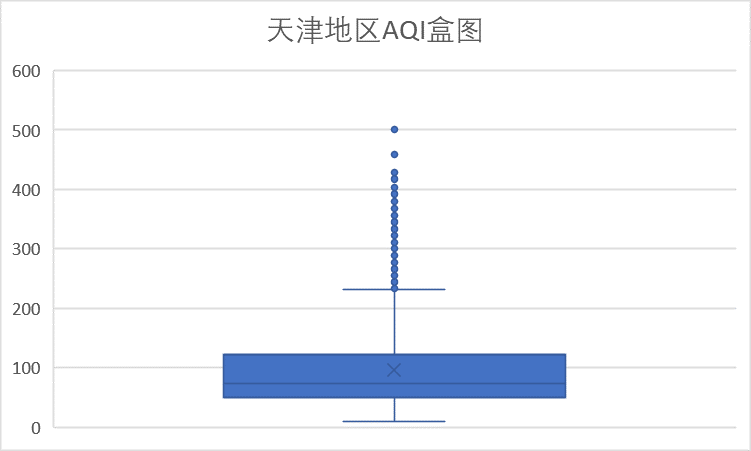
下面我们针对各检测指标进行分析及可视化。
(1)PM 指标
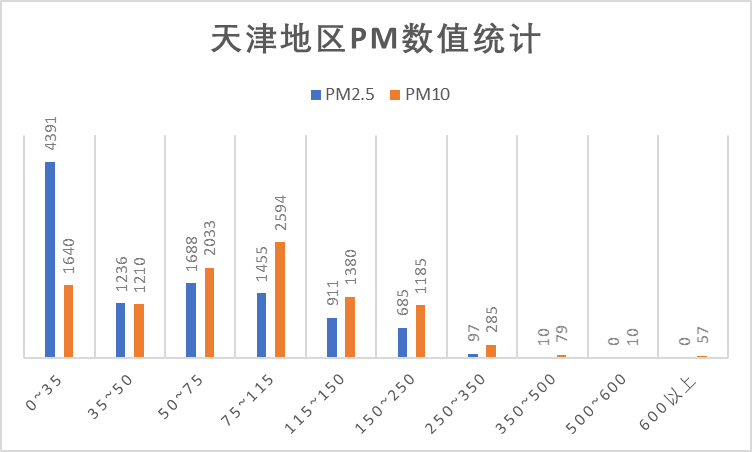
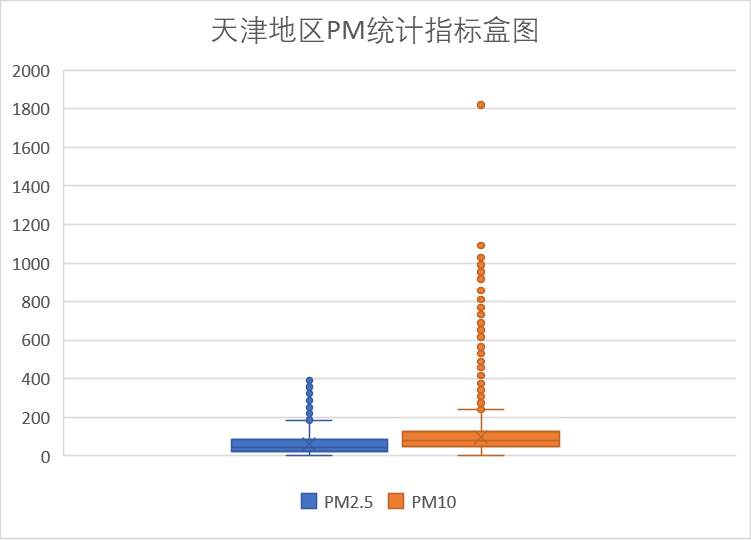
对照浓度限度表,从上面的数值统计图以及盒图我们可以看到,在PM指标上多数统计数据优于中度污染的限值内,良占比较高。
(2)CO 指标
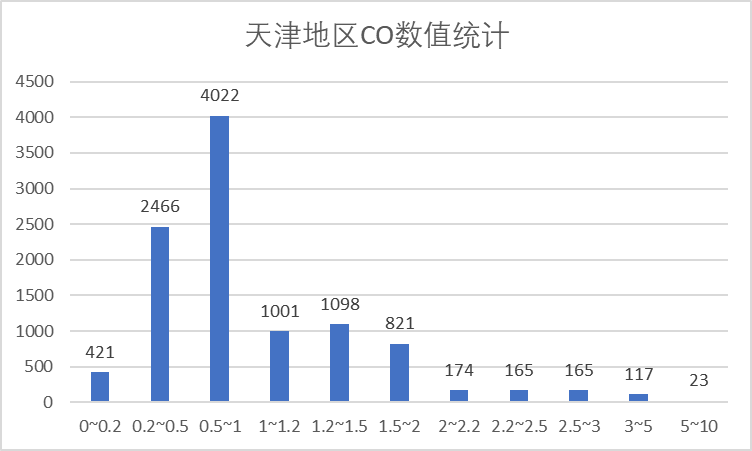
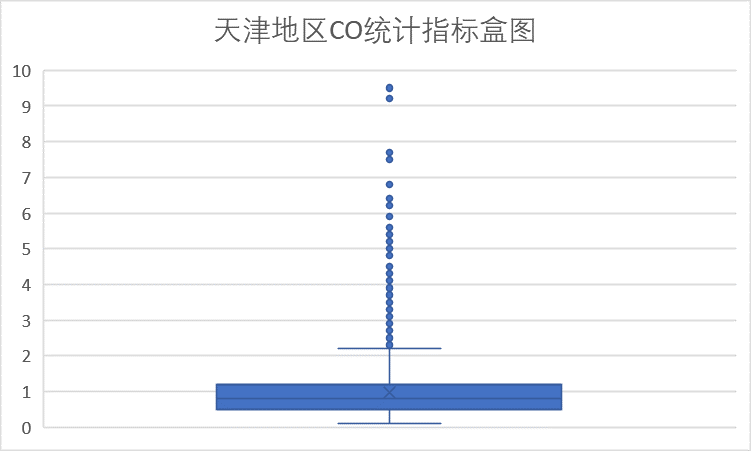
从上面两图可以看到CO指标大部分在优范围内,且数据偏向于优范围。
(3)NO2 指标
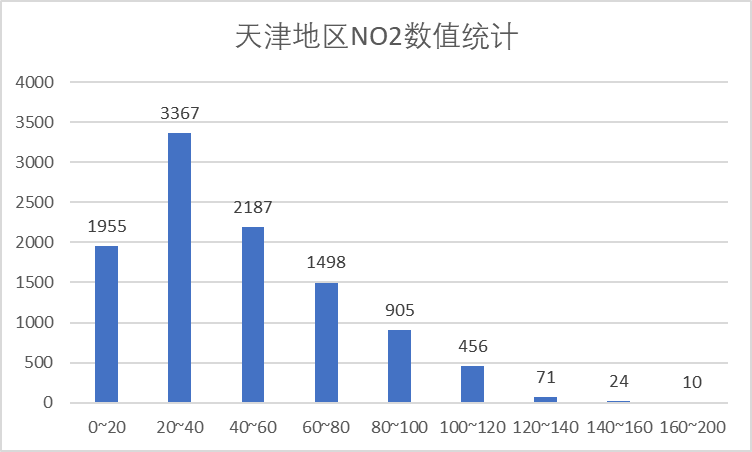
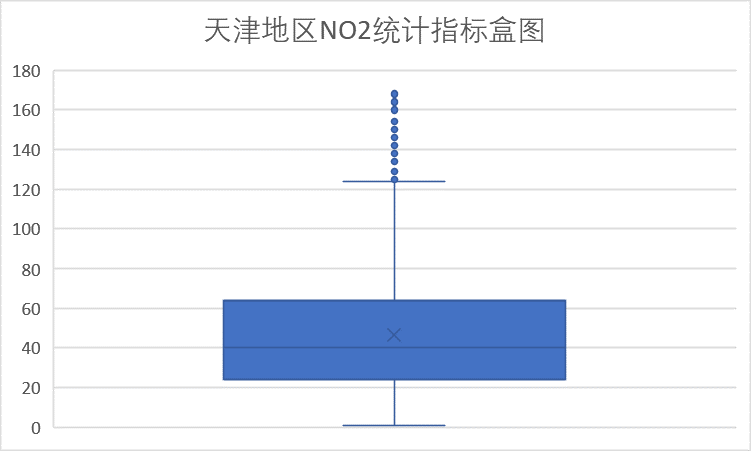
可以看到NO2浓度均小于良范围限值,因此NO2指标检测结果较好。
(4)O3 指标
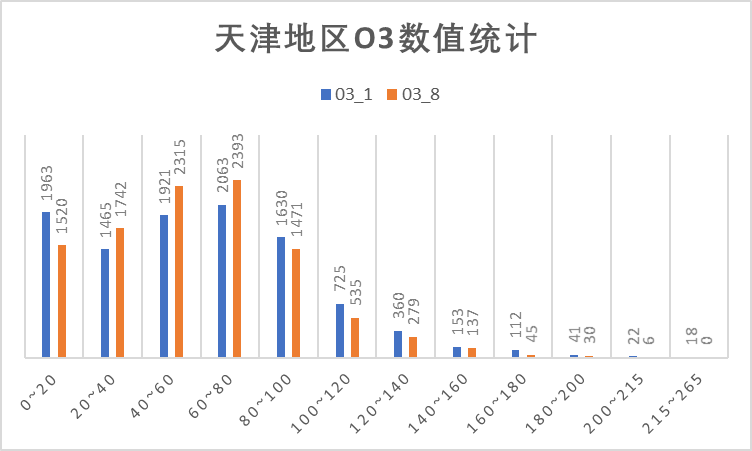
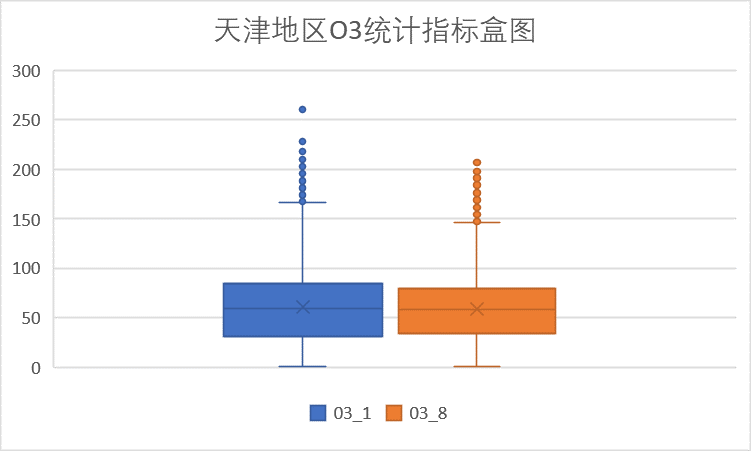
O3指标包括O3_1和O3_8两部分,对照浓度限度,这两个指标大部分在优良范围内,且优占比高。
(5)SO2 指标
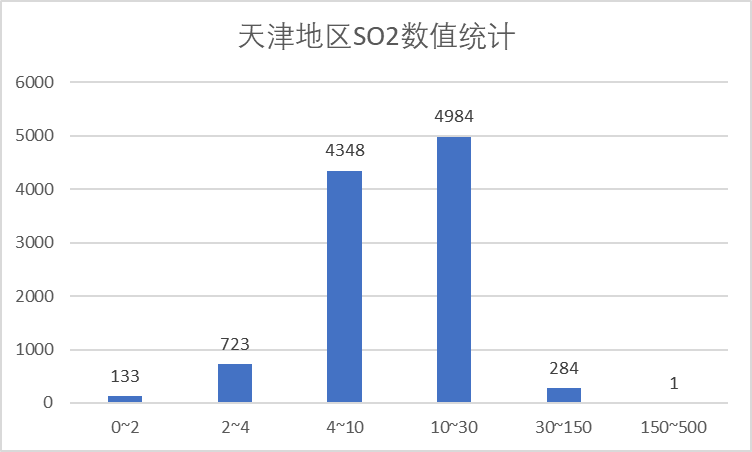
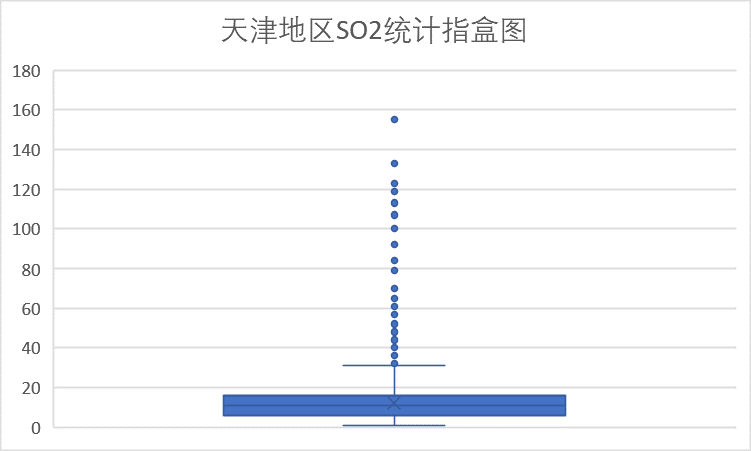
SO2浓度绝大多数150以内,只有一个数据点超过了150,因此该指标测量结果较好。
从以上分析中我们可以看到在统计时间内,天津地区的各项指标多在良及以上。相对来说PM对空气的影响较高。
各监测点分析
下面对各监测点AQI数据进行统计分析。
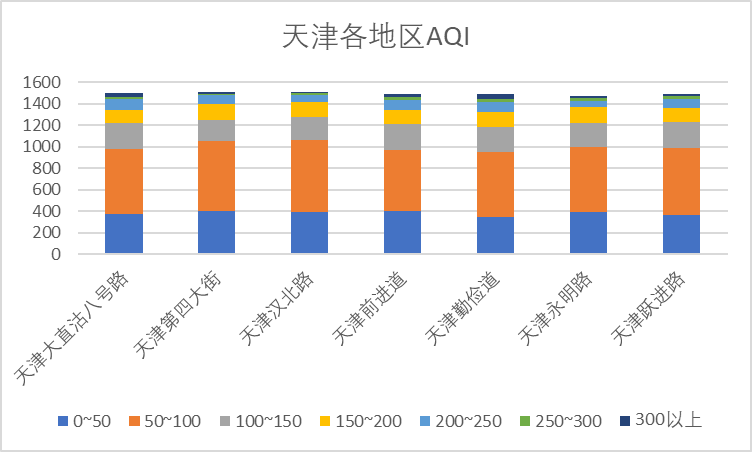
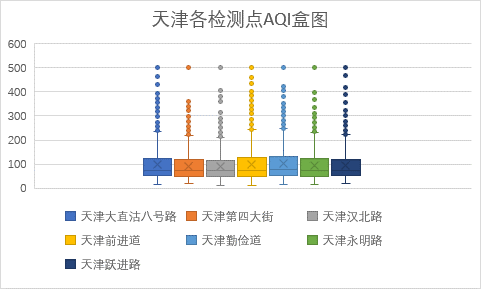
上图为各监测点的AQI数据统计,从图中我们可以看到,各监测点数据较为平均,空气质量为优及良的数量最多,良占比较大存在轻度污染,中度污染和重度污染明显减少。
天津地区每月数据分析
(1)每月AQI分析
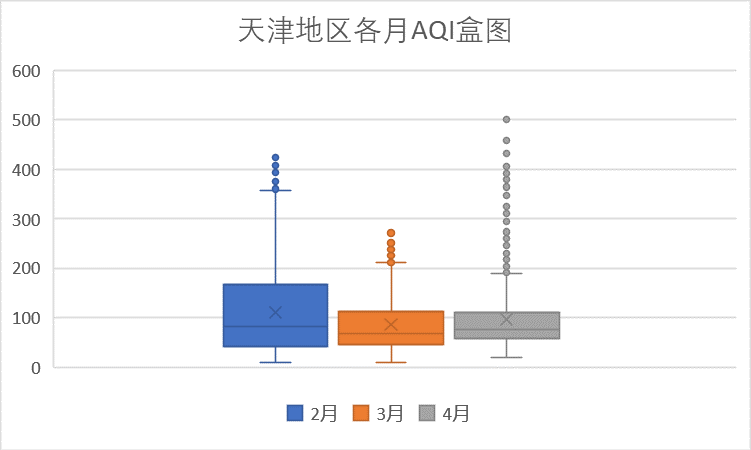
从盒图可以看出,3月和4月数据整体波动性不是很大,但4月存在明显的空气质量为严重污染的情况,离群点较多。2月数据整体较3和4月份差一些。
(2)各检测指标分析
下面我们针对各检测指标按时间进行分析。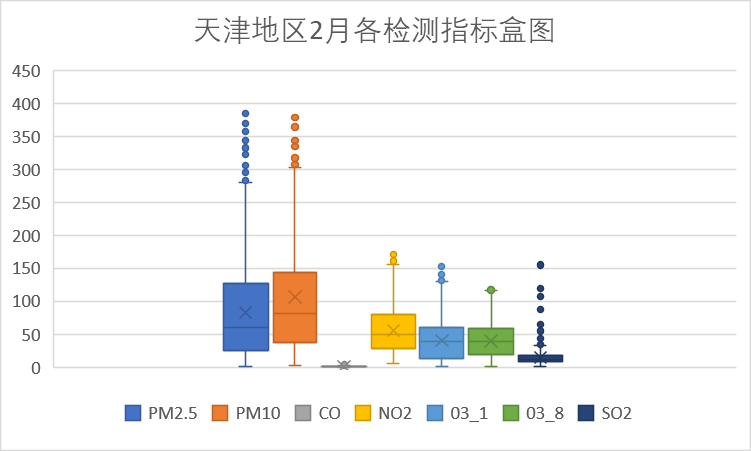
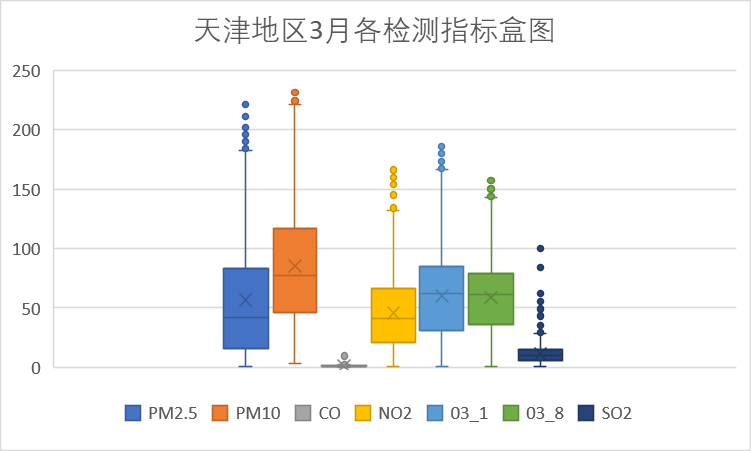
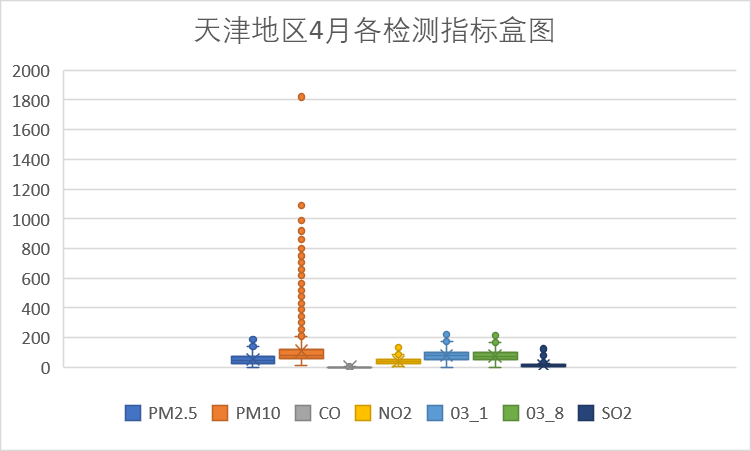
以上是每个月的各检测指标盒图,从图中可以看到PM10指标在4月存在偏高的数据,其余各检测指标无明显的波动。从图中我们还可以看到,PM尤其是PM10对天津空气质量的影响较大。
3. 模型选取
建立预测模型对京津冀地区的雾霾进行预测,属于回归问题的预测,使用的数据为北京、天津、河北的监测点数据,时间范围为2019年2月10日至2019年4月23日,使用的数据特征项有监测点名称、时间、空气质量指数(AQI)、PM2.5细颗粒物、PM10可吸入颗粒物、一氧化碳(CO)、二氧化氮(N02)、臭氧1小时平均(O3_1)、臭氧8小时平均(O3_8)、二氧化硫(SO2),预测的结果(标签)为空气质量指数(AQI),也可以对其他的环境指标进行预测。
使用基于LSTM和GRU的深层循环神经网络预测模型、基于全局注意力机制的神经网络预测模型、基于岭回归的神经网络预测模型等三种模型对京津冀地区的雾霾进行预测,并对比实验结果,选择每个地区最适合的雾霾预测模型。
雾霾预测属于序列数据的预测,并与时间相关联,循环神经网络适用于处理和预测序列数据,但普通循环神经网络在解决长期依赖问题时效果欠佳,长短期记忆网络(LSTM)可以很好地解决长期依赖的问题,LSTM在单元结构中加入了输入门、遗忘门、输出门。门控循环单元(GRU)是LSTM的变体,相比较于LSTM,GRU的结构更简洁,并且依然有不错的处理效果。所以使用基于LSTM和GRU的深层循环神经网络预测模型。
全局注意力机制可以为不同时间步的隐藏状态分配不同的权重,使模型可以获得对当前输出影响最大的信息,可以解决雾霾预测任务中信息传输距离过长的问题,所以使用基于全局注意力机制的神经网络预测模型。
岭回归是一种适用于回归问题的线性模型,解决了线性回归的过拟合问题和通过正规方程求解过程中出现的矩阵乘法不可逆两类问题,所以使用基于岭回归的神经网络预测模型。
目前实现了基于LSTM和GRU的深层循环神经网络预测模型、基于岭回归的神经网络预测模型,并进行了雾霾预测实验,进行了实验结果对比。
在基于LSTM和GRU的深层循环神经网络预测模型中,在神经网络的结构中,输入层为空气质量数据,数据项为经过标签编码的监测点名称、空气质量指数(AQI)、PM2.5细颗粒物、PM10可吸入颗粒物、一氧化碳(CO)、二氧化氮(N02)、臭氧1小时平均(O3_1)、臭氧8小时平均(O3_8)、二氧化硫(SO2)。时间项在数据预处理时用来给数据排序,转换成监督学习的格式后,训练样本便包含了时间,所以在输入层不再输入时间,可以加快网络的计算。
在输入层之后,设置两层LSTM层或GRU层,在LSTM层或GRU层的下一层,设置全连接神经网络层(Dense层)以防止之前的LSTM层或GRU层叠加效果不稳定,Dense层的神经元个数为LSTM或GRU层的一半。使用的循环神经网络模型将LSTM层、GRU层结合,并与只使用LTSM层、只使用GRU层进行比较。实现了三种结构的循环神经网络:(1)输入层+LSTM层+GRU层+Dense层+Dense层+输出层;(2)输入层+LSTM层+LSTM层+Dense层+Dense层+输出层;(3)输入层+GRU层+GRU层+Dense层+Dense层+输出层。
在基于岭回归的神经网络预测模型中,网络结构为全连接神经网络结构,即通过输入层、隐藏层、输出层计算损失函数,再通过梯度下降最小化损失函数。与线性回归不同的是,岭回归在损失函数中加入了正则化项,引入的是L2范数惩罚项。
雾霾预测模型的源码地址为https://github.com/18811578511/DataMining_FogPredict/tree/master/model
4. 挖掘实验的结果
目前使用基于LSTM和GRU的深层循环神经网络预测模型和基于岭回归的神经网络预测模型对京津冀地区的雾霾进行了预测。预测的空气质量指数属于回归问题,所以评价指标使用均方根误差(RMSE)和平均绝对误差(MAE)。均方根误差对极大值和极小值有很好的反映,可以较好地反映预测的精确度,雾霾预测结果的均方根误差在25以内是较理想的;平均绝对误差使评价指标不会出现正负相抵的情况,可以更好地反映预测误差的真实情况。定义单一评价指标$RMSE_MAE=0.5(RMSE)+0.5(MAE)$,$RMSE_MAE$越小,说明模型预测结果越准确。
此处以北京地区的雾霾预测为例,选取北京地区2019年2月10日至2019年4月23日共11个监测点的监测数据,以8:1:1的比例将数据集划分为训练集(TrainSet)、验证集(DevSet)、测试集(TestSet),使用前24小时的监测点数据对下一时刻的AQI进行预测。
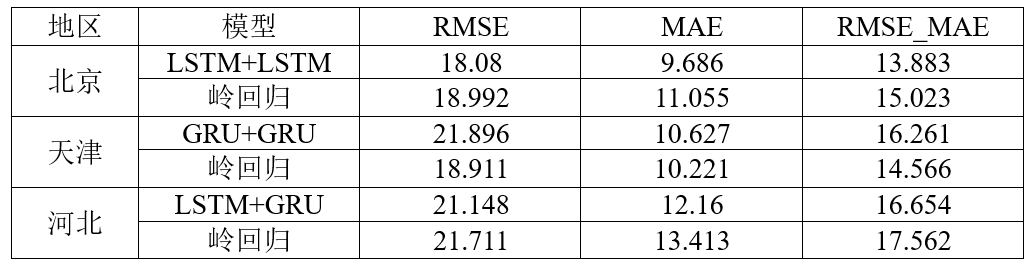
基于LSTM和GRU的深层循环神经网络预测模型使用的三种结构的实验结果如下图所示,由EMSE_MAE可以得到,预测北京地区的空气质量指数时,首层神经元个数为64的输入层+LSTM层+LSTM层+Dense层+Dense层+输出层的预测模型效果最好,平均RMSE为18.08,平均MAE为9.686。
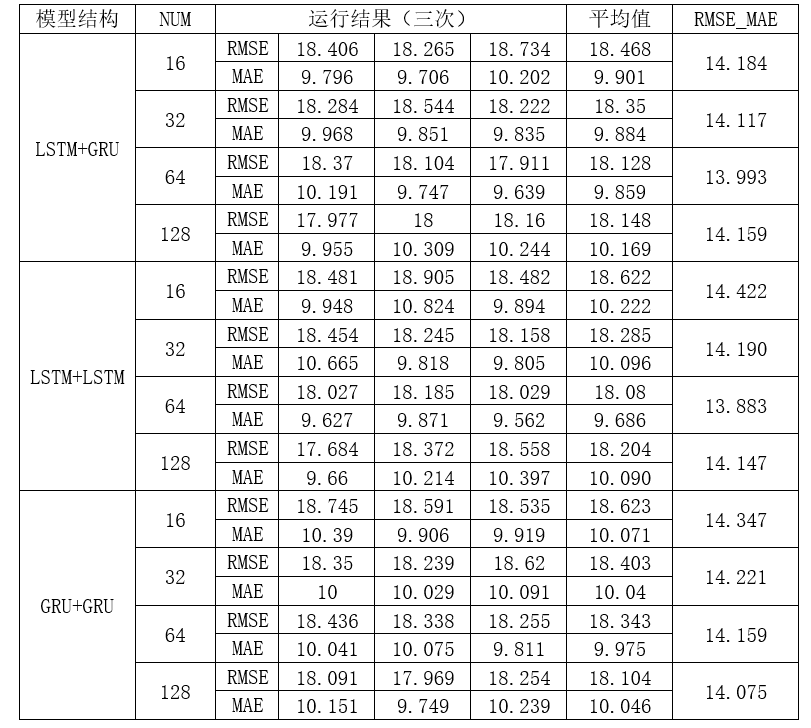
基于岭回归的神经网络预测模型经过训练集学习之后,在验证集的RMSE为18.992, MAE为11.055。
两种方法在京津冀地区的雾霾预测对比结果如下图所示。由实验结果可得,在北京地区和河北地区,循环神经网络的预测效果要好于岭回归的预测效果;在天津地区,岭回归的预测效果好于循环神经网络的预测效果。原因是天津地区的监测点数据加少,岭回归对数据的拟合更占优势;北京地区和河北地区的监测点数据较多,使用LSTM层或GRU层的循环神经网络对数据的拟合更准确。
5. 存在的问题
(1)在获取的数据中,有的环境指标存在缺失值,虽然我们使用了均值补全的方法进行填充,但是可能会对预测的结果产生一定的影响。
(2)在将环境数据转换为监督学习的格式时,因为要预测未来时刻的数据,存在数据的上下平移操作,因此会造成少量的环境指标数据缺失,在对模型进行训练时可能会产生一定的影响。
6. 下一步工作
目前实现了基于LSTM和GRU的深层循环神经网络预测模型和基于岭回归的神经网络预测模型,并且对京津冀地区的雾霾进行了预测,进行了实验对比。下一步工作将实现基于全局注意力机制的神经网络预测模型对京津冀地区的雾霾进行预测,在时间允许的情况下,对其他地区的雾霾进行预测。
将三种雾霾预测模型的预测效果进行对比,提高模型预测的准确度,完成最终的报告。
7. 任务分配与完成情况
- 严超:数据获取及预处理、报告书写,已完成。
- 薛晓军、于敬楠:模型选取和结果分析、报告书写,基本完成。
- 臧梓硕、白思萌:数据分析与可视化、报告书写,已完成。