注意: 上方的内容不要删除
基于流日志的流量预测
成员
- 马许:3220180840
- 谭祥:3220180856
- 夏旸:3220180880
问题描述
1.1 问题背景分析
1.1.1 流日志
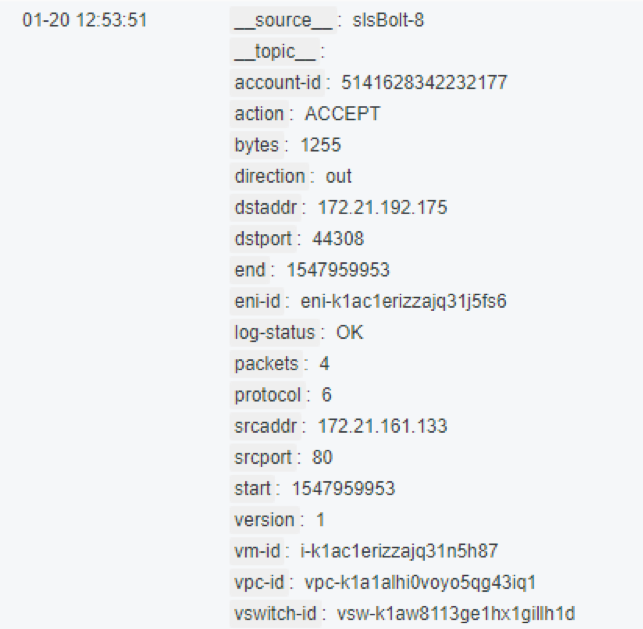
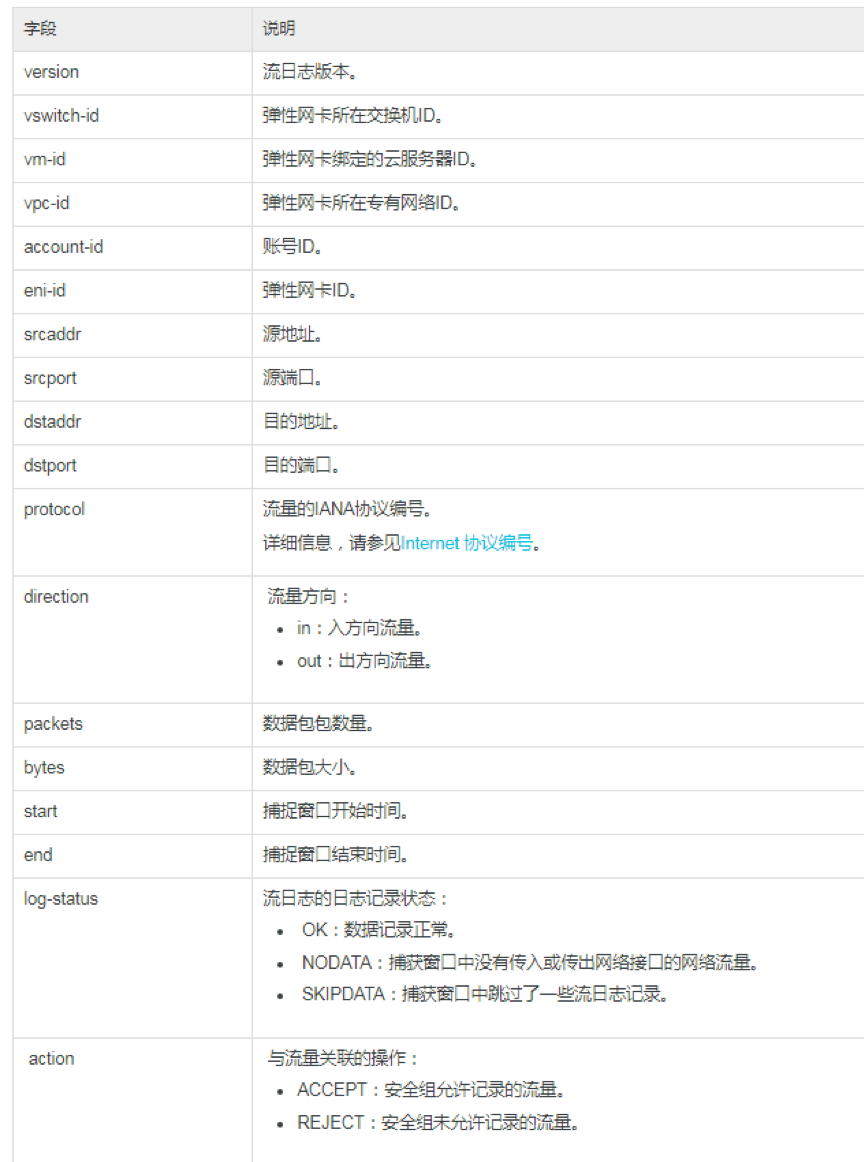
流日志可以记录VPC网络中弹性网卡(ENI)的传入和传出流量信息,帮助检查访问控制规则、监控网络流量、进行网络故障排查。利用 VPC 流日志,您可捕获传入/传出 VPC 中弹性网卡 IP 流量。创建流日志后,可以查看和检索其数据,或用将指定流日志投递其它产品分析或存储。 五元组:指的是源IP地址,源端口,目的IP地址,目的端口和传输层协议。 IPFIX即IP Flow Information Export,IP数据流信息输出,它是由IETF公布的用于网络中的流信息测量的标准协议。该协议主要在于: 统一IP数据流的统计、输出标准,这使得网络管理员很容易地提取和查看存储在这些网络设备中的重要流量统计信息。 输出格式具有较强的可扩展性,因此如果流量监控的要求发生改变,网络管理员也可通过修改相应配置来实现,不必升级网络设备软件或管理工具。 为了较完整的输出数据,IPFIX缺省使用网络设备的七个关键域来表示每股网络流量:源IP地址,目的IP地址,TCP/UDP源端口,TCP/UDP目的端口,三层协议类型,服务类型(Type-of-service)字节,输入逻辑接口 图一为1月20号12点53分51秒时刻的一条流日志信息。
1.1.2 云环境网络流量
云计算在今天已经是日渐成熟的产业,小中型的企业都相信云计算的稳定性和高性价比,现在的商用APP都倾向于把应用“上云”减少成本和维护费用。而云服务商像阿里则承载着众多应用的每日负载,责任重大,保证任何时候服务器和带宽都处于稳定状态不发生或者减少意外情况的发生。通常网络带宽是随着时间而改变的,例如双十一的时候网络会急剧增加到平时的十倍或百倍以上,平常时候网络的流量也有一定的pattern隐含在流量之中。
1.2 问题描述
流日志可以用于监测网络的运行情况,通过对流日志做聚合统计分析可以预测未来的网络流量。我们想通过时序统计模型来预测网络的带宽,并且准备了几种不同的模型分别对数据做预测,比较哪种模型更好的模拟真实数据。
2.1 数据准备
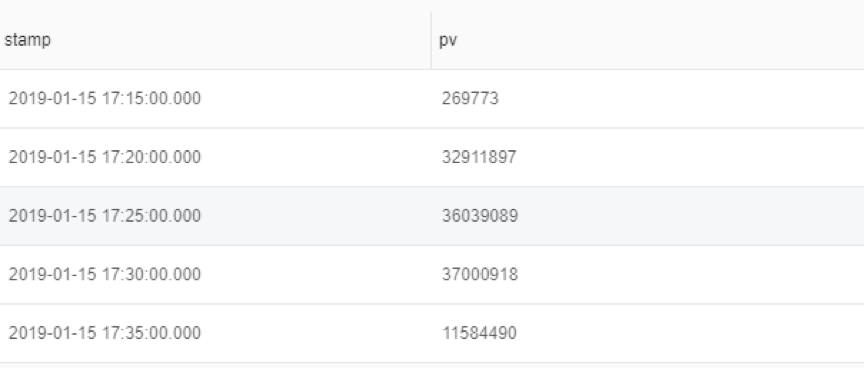
我们找来了阿里云内部的一个真实流日志数据集,是YY公司在阿里云服务器上线运行时产生的25分钟左右的数据。通过图3可以看出数据在17:20-17:35这15分钟之内比较稳定,之前和之后的数据包含了一些噪声不适合做统计分析。我们取出这15分钟数据,并把前十分钟数据用作统计数据,后五分钟用作验证数据。
2.2 模型建立
时序统计预测函数:ar、ma、arma、arima 如果一个时间序列经过平稳性检验后得到是一个平稳非白噪声序列,那么该序列中就蕴含着相关性的信息。 在统计学中,通常是建立一个线性模型来拟合该时间序列的趋势。其中,AR、MA、ARMA以及ARIMA都是较为常见的模型。
2.2.1 AR(Auto Regressive Model)自回归模型
AR是线性时间序列分析模型中最简单的模型。通过自身前面部分的数据与后面部分的数据之间的相关关系(自相关)来建立回归方程,从而可以进行预测或者分析。下图中展示了一个时间如果可以表示成如下结构,那么就说明它服从p阶的自回归过程,表示为AR(p)。其中,ut表示白噪声,是时间序列中的数值的随机波动,但是这些波动会相互抵消,最终是0。theta表示自回归系数。
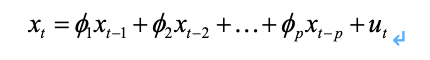
所以当只有一个时间记录点时,称为一阶自回归过程,即AR(1)。
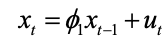
2.2.2 MA(Moving Average Model)移动平均模型
通过将一段时间序列中白噪声序列进行加权和,可以得到移动平均方程。如下图所示为q阶移动平均过程,表示为MA(q)。theta表示移动回归系数。ut表示不同时间点的白噪声。
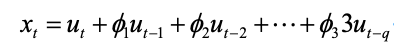
2.2.3 ARMA(Auto Regressive and Moving Average Model)自回归移动平均模型
自回归移动平均模型是与自回归和移动平均模型两部分组成。所以可以表示为ARMA(p, q)。p是自回归阶数,q是移动平均阶数。
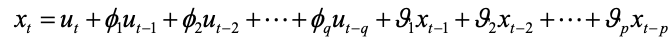
从式子中就可以看出,自回归模型结合了两个模型的特点,其中,AR可以解决当前数据与后期数据之间的关系,MA则可以解决随机变动也就是噪声的问题。
2.2.4 ARIMA(Auto Regressive Integrate Moving Average Model)差分自回归移动平均模型
同前面的三种模型,ARIMA模型也是基于平稳的时间序列的或者差分化后是稳定的,另外前面的几种模型都可以看作ARIMA的某种特殊形式。表示为ARIMA(p, d, q)。p为自回归阶数,q为移动平均阶数,d为时间成为平稳时所做的差分次数,也就是Integrate单词的在这里的意思。
具体步骤如下: 获取被观测系统时间序列数据; 对数据绘图,观测是否为平稳时间序列;对于非平稳时间序列要先进行d阶差分运算,化为平稳时间序列; 经过第二步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数ACF 和偏自相关系数PACF,通过对自相关图和偏自相关图的分析,得到最佳的阶层 p 和阶数q 由以上得到的d、q、p,得到ARIMA模型。然后开始对得到的模型进行模型检验。
2.3 预期的结果
在折线图中反映出真实曲线和预测曲线的对比,按照模型对比应该是arima的拟合效果优于arma优于ar,能基本拟合真实的曲线。
项目评估
实验利用21分到35分的数据进行训练拟合,分别利用三阶AR、三阶ARMA、三阶ARIMA(差分系数为二阶)三种时序分析模型来进行拟合。 根据前14分钟的真实数据训练好三种模型,再对后4分钟的数据进行预测,并且与实际数据相对比。 图4-6分别为三种模型对数据的拟合和预测,并且与实际数据相对比。
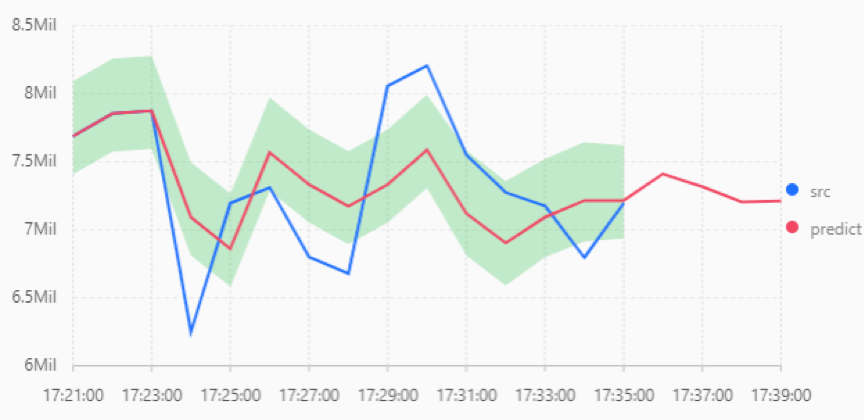
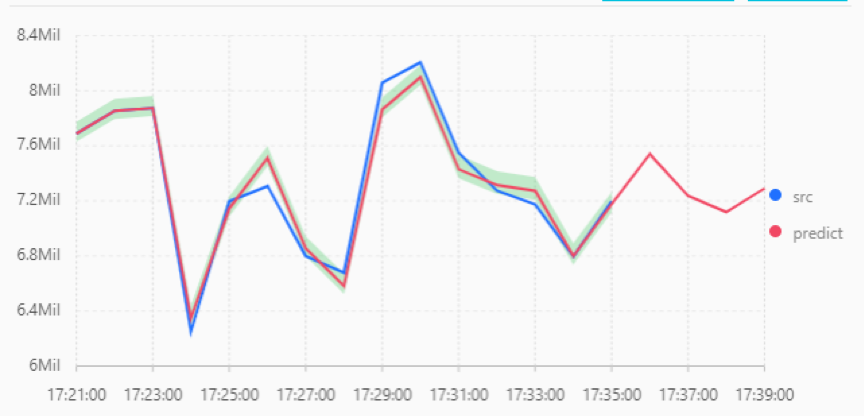
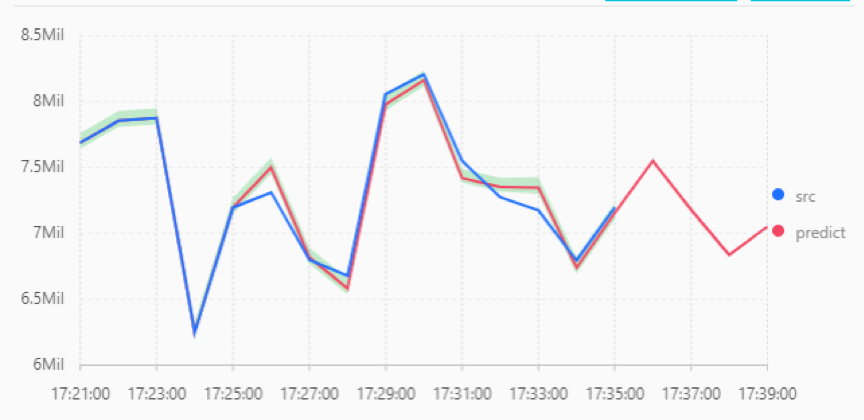
可以看出三阶ARMA和三阶ARIMA模型对数据拟合的效果比较好,三阶AR模型对数据拟合的效果一般,其中三阶ARIMA模型拟合效果最好。
项目分工
- 马许:数据处理、可视化
- 谭祥:文档撰写
- 夏旸:文档撰写